一行命令,丢包率从15%直降为0%
有没有遇到这种情况,网络带宽使用率只有50%,CPU使用率也很低,但是经常会出现网络丢包的告警,伴随着响应超时和请求缓慢,应用日志中还查不到记录。
那么大概率就是受到了这个参数设置的限制,net.core.netdev_max-backlog。
查看系统当前的值
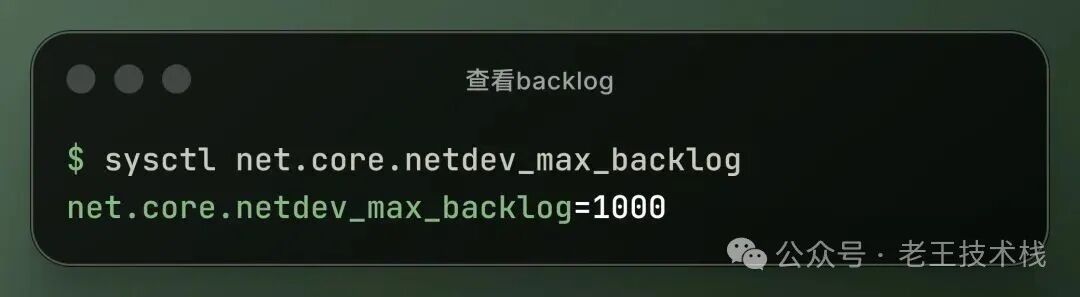
它是Linux 内核网络子系统中一个控制网络接收队列长度的参数。新到的数据包必须先在内核的 backlog 队列里排队等候。
目前主流的发行版本这个值默认为1000,意味着一旦瞬间有超过1000个数据包涌来而CPU 来不及处理,超出的部分会被内核直接丢弃,不通知任何应用程序,这也是我们为什么应用查不到记录的原因。
显然,这个值在真实的高PPS场景中是非常脆弱的,只要上游出现一次网络突刺就极有可能导致backlog队列就会瞬间溢出。
用iperf3模拟高频UDP请求对比下这个参数调整前后的变化
先启动一个新的窗口实时观察backlog 丢包情况

正常情况下,所有 CPU 的dropped列应为 0
服务端启动 iperf3 监听

客户端发起压测
观察调整前默认值1000 监控端输出
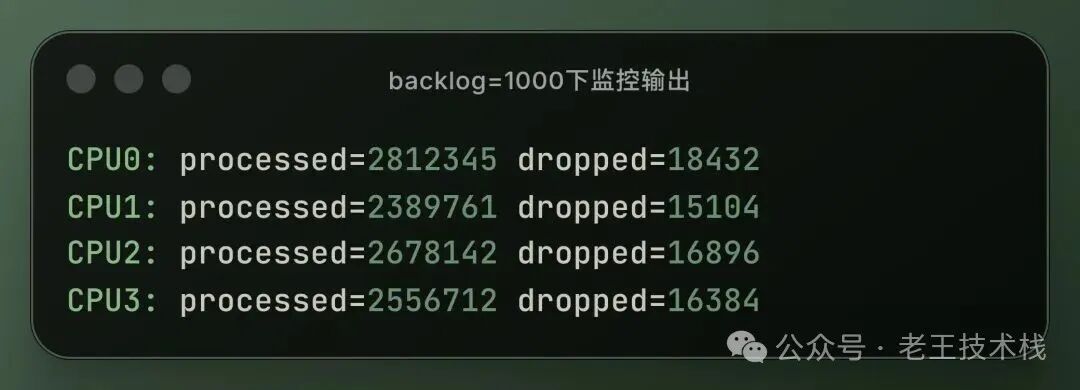
可以看到每个 CPU 都有明显丢包,丢包率大约为15%。
修改值为5000后重新压测观察
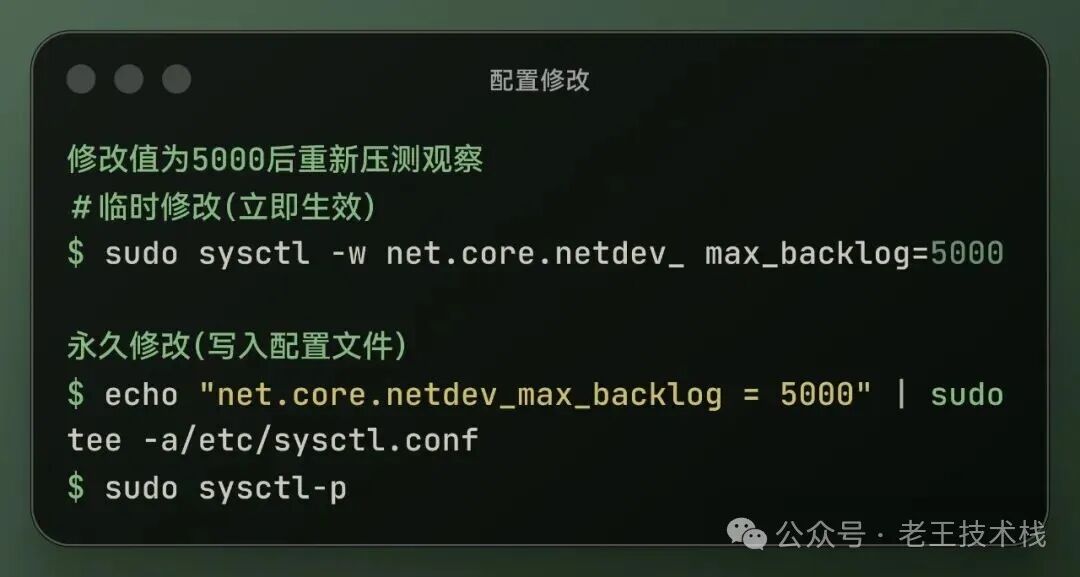
再次执行压测命令,观察监控窗口
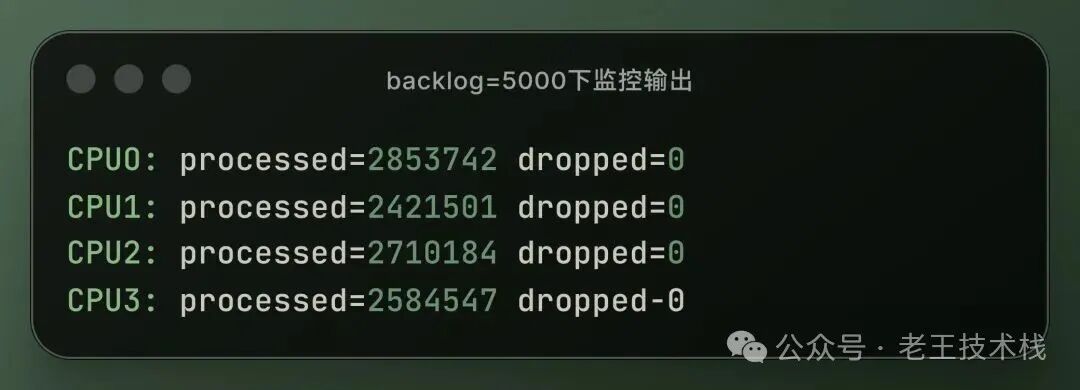
所有 CPU 的 dropped均为 0,丢包率0%,网卡dropped计数器也停止增长。
丢包率从15%下降到了 0%。
那真实环境需要调整多大合适呢?
常规场景调整到5000~10000;
高PPS场景调整到30000~50000(需压测验证)。
需要注意的是,如果还想进一步调优就需要配合 RPS提升软中断能力。
调大 netdev_max_backlog 只是解决了队列容量问题,但如果没有足够的软中断处理能力,队列依然会持续积压。
提高软中断处理能力的就是是让多个 CPU核共同分担网络收包处理。
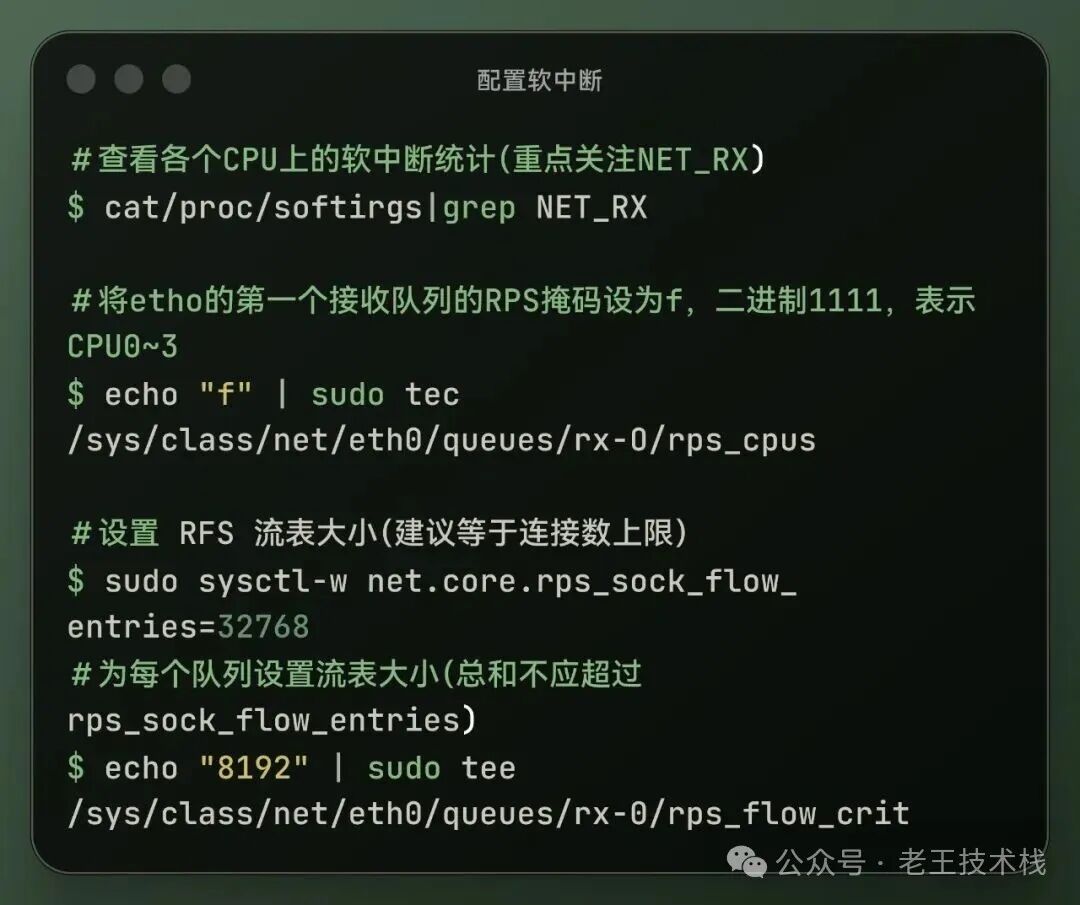
开启RPS(Receive PacketSteering)LRPS将收到的数据包哈希分发到多个CPU 的 backlog 队列上,让软中断并行处理。
开启 RFS(Receive Flow Steering): RFS 是 RPS 的升级版,能将同一条流(例如同一个TCP连接)数据包送到同一个CPU
net.core.netdev_max backlog是 Linux 网络接收路径上容易被忽视的参数,目前的默认值很有可能成为高 PPS场景下的网络瓶颈。